


sync와proc sys vm drop_caches차이점
안녕하세요
오늘은 sync랑 drop_caches 라는 거에 대해서 알아볼 겁니다.
이것은 약간 난이도가 있습니다 한번 천천히 한번 말씀을 좀 드려 보도록 할게요
우선은 sync, drop_caches 대한 차이점을 알기 위해서 기본적으로 메모리 동작과 caches개념을 정확하게 이해하는것 굉장히 중요한데요
일단은 메모리입니다
우리가 사용할 수 있는 메모리가 8G, 16G 이렇게 있을 때
그걸 덩어리 통째로 쓰는게 아니라요
이렇게 4키로바이트라는 조각 단위로 잘게 잘게 나눠 가지고 관리를 하게 됩니다
리눅스는 일단 기본적으로 이런식으로 관리를 하게 되고요
우리가 프로그래밍 돌면서 메모리 동작을 할 때는 페이지 단위로 할당을 해주고 해지를 하기도 합니다
그런데 char 나 int, float 이런식으로 1바이트,4바이트,8바이트 이런식으로도 할당을 하게 되는데 그럼 무조건 4KB 할당을 하게 되는 거냐 실제로는 4KB씩 할당이 됩니다
하지만 실제로 그 4KB 안에서 1바이트 4KB 안에서 4바이 이런 식으로 사용하는 형식이 있거든요
그래서 이런 것들을 조금 더 정확하게 이해하시려면 가상 메모리 개념이 좀 있으셔야 됩니다
물리 메모리 조각 자체를 관리하고 물리 메모리 조각이 어떻게 쓰이는지를 지금 이해를 해 볼 건데 이게 실제로 사용이 될 때는 가상메모리의 맵핑이 돼서 사용하게 되거든요
그래서 어떤 식으로 동작하는지 가상 메모리 메커니즘을 정확하게 이해하시려면 아무래도 리얼리눅스 강의 중에서 시스템 핵심적인 조금 더 나아간다면 커널 중급A 이 정도를 해 주셔야지 정확하게 개념을 잡으실 수는 있을겁니다.
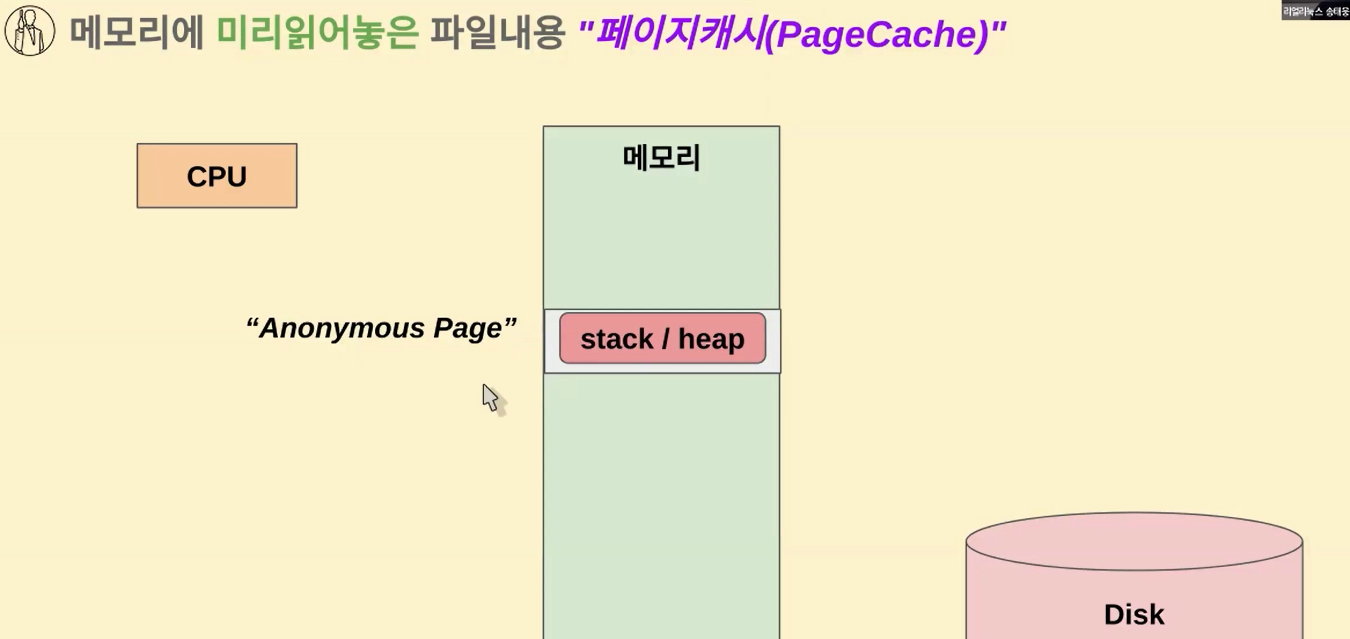
다음에 가상 메모리 개념도 한번 살펴보도록 하겠습니다
우리가 일반적으로 사용하는 메모리는 Anonymous Page라고 보통 말을 하게 되요
스택(stack)이라든지 힙(heap) 공간으로 사용하는 용도를 얘기하게 되는데 같은 페이지여도 어떤 용도로 쓰냐에 따라서 네이밍이 달라집니다
일반적으로 int,char,float 이런식으로 배열을 사용하거나 전역변수 지역변수 이렇게 쓰는 것들은 전부 다 Anonymous Page고요
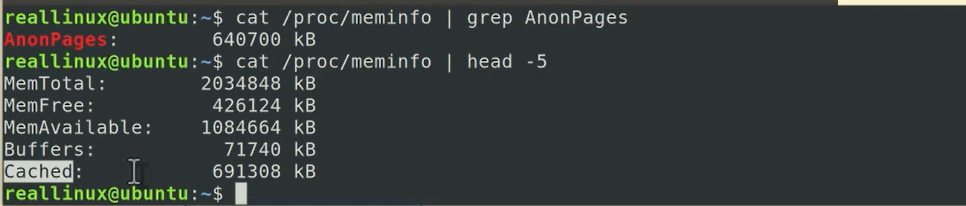
우리가 명령어를 살펴보게 된다면 proc/meminfo 안에서 grep Anonpages 했을때 Anonpages를 얼마나 쓰고 있는지를 확인 해 볼 수 있는거죠
알고 있는 개념들을 명령어를 통해서 추적하거나 확인하거나 모니터링 해 보거나 이렇게 증명하는 습관 굉장히 중요하고요
어쨌든 이런 것들이 스택(stack)이나 힙(heap) 용도로 쓰는 페이지들을 얘기하게 됩니다
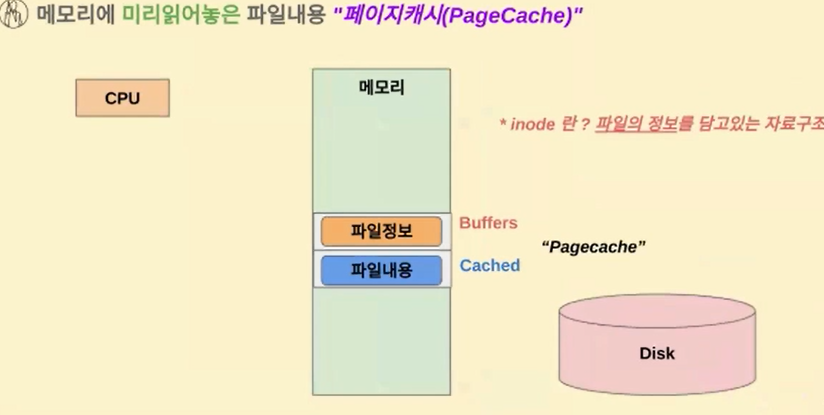
그런데 그거 말고도 똑같은 페이지 조각이지만 이거를 어떤 용도로 쓸 때 파일 정보나 파일 내용을 담는 용도로 쓸 때는 이거를 pagecache 라고 부르게 됩니다
이때 sync 랑 drop_caches 차이점 알아본다고 했는데 이거는 전부 다 pagecache 대한 얘기예요
이 파일 정보나 파일 내용을 담는 이런 페이지들을 아까랑은 다르죠 Anonpages가 아니라 pagecache 라고 부르게 됩니다
그리고 여기서 말하는 파일 정보는 아이노드(inode: 파일정보) 정보 같은걸 뜻하게 되는데요
디스크를 파일 시스템 포맷을 뭐 쓰냐에 따라서 달라질 수는 있겠지만 아이노드(inode: 파일정보)라고 해서 파일의 정보를 갖는 아이노드갯수들도 사실 정해져 있어요 근데이 아이노드라는 거는 결국에 파일이 정보를 담는 자료구조라고 생각을 하시면 되겠고요
예를 들어서 큰 영상 파일이든 텍스트 파일 작은 텍스트 파일이든 파일의 정보 아이노드 크기는 그렇게 차이가 많이 나지 않겠죠
그래서 이 정보를 나타내는 Buffers와 내용을 나타내는 cached는 용량 차이가 좀 납니다
이것도 증명을 해보도록 할게요
이 부분에서 head -5 를 보시게 되면 total, free, available 이런 것들이 나오게 되는데 available관련되서도 지난 영상에서 한번 설명을 좀 드렸었죠 여기 보이는 그 Buffers, Cached 이것을 한번 살펴보게 되면 Buffers 도 pagecache Cached 도 pagecache 그러니까 페이지가 파일 디스크에 대한 블록을 유지하고 있으면 전부 다 pagecache라고 말하면 됩니다 하지만 pagecache중에서도 정보를 담고 있으면 Buffers라고 부르게 되는 거고 pagecache 중에서도 데이터 블록을 담고 있으면 Cached라고 말하면 되죠
아무래도 데이터 블록을 담고 있기 때문에 좀 더 크기가 큰 거를 볼 수가 있습니다
이게 굉장히 중요한 부분이라고 보실 수가 있는 거고요
현재 말씀드리는 내용들은 실제로 리눅스 커널 소스 코드의 분석 결과를 토대로 증명해서 말씀을 드리는것이기 때문에 헷갈리지 않고 바로 받아들이셔도 상관은 없습니다 이런 식으로 말씀을 좀 드릴 수가 있는데요
sync 랑 drop_caches 라면 어떤 식의 동작이 되는지도 한번 이어가보도록 하겠습니다
일단은 sync 하는 것과 cache하는 것은 pagecache를 다루게 되는 건데 Dirty pagecache를 Clean pagecache로 만드는 것과 Clean pagecache를 해지를 하는 이런 차이가 있어요 일단은 Dirty pagecache 개념입니다 디스크 내용과 차이점이 있는 거예요
아무래도 우리가 디스크를 읽을 때 파일 IO로 할 때는 리눅스는 기본적으로 Buffered I/O 라는 개념을 사용하게 돼요
기본적으로 그런 식으로 되는데 이게 무슨 말이냐면 디스크에 있는 내용을 일단 메모리에 유지하면서 read/write 하겠다는 거고 read/write 를 했을 때 항상 메모리를 기준으로 먼저 read/write 를 하게 됩니다
이게 Buffered I/O 개념이에요 물론 조금 더 깊게 들어가면 이것에 대해서도 할 얘기들이 정말 많이 있지만 우선은 이제 핵심적인 개념만 말씀을 드려보도록 할게요
언제나 그렇듯이 너무 깊은 depths를 처음부터 욕심을 내기보다는 핵심적인 1depths, 2depths, 3depths 이런 것들을 좀 다루시고 그 다음에 4,5,6depths... 이런 식으로 내려가는데 제가 생각했을 때 5depths, 6depths 정도 되는 레벨이 전체 depths가 10depths정도라고 봤을때 5depths, 6depths 리눅스 커널 소스 코드 중에서도 함수 Function 단위 주요 코드, 자료구조 이 정도 수준이라고 생각하거든요
그 정도 레벨까지 들어가면 저는 충분한 기본기를 갖췄다라고 생각하고 중급 레벨 이상의 실력이라고 생각합니다
이 정도 되면 특정 케이스에 대해서도 깊이 파고들고 알아서 갈 수가 있어요
트레이싱 도구 다양한 명령어 증명 도구들 분석, 모니터링 이런 것들을 같이 활용해 주시게 되면 리눅스에서 어떻게 보면 모르는게 없을 수가 있다
그러니까 물론 전부 다 지식적으로 알고 있는 건 아니지만 알아낼 수 있는 지혜가 있으니까 할 수가 있는 거죠
리얼리눅스안에 있는 교육들도 전부 다 이런 목표로 가고 있습니다.
약간 옆으로 샜는데 다시 한번 말씀을 좀 드려보도록 할게요
자 우리가 메모리 중에서 메모리 조각 하나를 페이지라고 부르게 되는데 어떤 용도로 쓰냐에 따라서 네이밍이 달라지죠
그런데 anonymous 로 쓰는 거 빼고 pagecache로 쓰는 것들 중에서 디스크 내용과 달라진 부분들이 있는 페이지들을 dirty cache라고 부르고
또 디스크 내용들을 다이렉트로 IO 하지 않고 Buffered I/O 개념을 말씀드리죠 그게 결국 pagecache 될 수가 있는 거고요
그리고 clean cache는 디스크라고 내용이 일치가 되어 있을 때 clean pagecache 라고 부를 수가 있게 됩니다
그런데 여기서 결국에 sync라는 동작 그러니까 내가 만약에 sync를 하게 되면 sync 명령어를 입력하거나 시스템 폴더 sync를 했을 때 dirty 부분들을 clean으로 바꾸는 걸 하게 되요 명령어로 한번 증명을 해 보게 되면 내가 만약에 free라는 명령어를 통해서 지금 buffcache 있는 부분을 봤어요 물론 이거는 실시간적으로 보는 것이기 때문에 약간씩 돌아가는 프로그램에 따라서 영향을 받아서 동일한 소리를 한다고 하더라도 약간씩 변화가 될 수도 있어요 물론 제가 지금 사용하고 있는 서버 환경에서는 별 다른게 돌아가는게 많지는 않기 때문에 큰 영향을 주고 있지는 않지만 실시간적으로 주는 서버들은 그냥 free만 하더라도 차이가 충분히 날 수는 있습니다
저도 지금 조금씩은 나오고 있죠 그래서 그거는 이제 감안해서 보셔야 되는 거고요 일단은 free 했을 때 지금 현재 buff/cache 부분이 있는 걸 볼 수 있어요
그런데 sync를 하고 나서 다시 한번 buff/cache를 본다고 하더라도 물론 약간의 차이점이 있지만 큰 차이점이 생기는 건 아닙니다
예를 들어서 크게 줄어들거나 크게 늘어나거나 이런 건 아니라는것을 볼 수 있어요
실제로 dirty cache >> clean cache 바꿀 뿐이니까
sync가 맞춰줄 뿐인것이기 때문에 sync명령어 sync 시스템 콜에 핵심 포인트라고 보시면 되겠습니다
하지만 이제 차이점을 한번 보면 /proc/sys/vm/drop_caches proc 밑에 있는 파일이나 시스템 밑에 있는 파일은 이제 커널 메모리하고 매핑되서
특수 파일들이죠 시스템 파일입니다
그래서 이런 것들을 echo 등을 통해서 write 한다던가 (cat 통해서) read 한다던가 이런 동작들이 결국엔 커널 프로그램과 동작이 되는 거고
시스템들을 다루는 특수한 파일들이라고 보시면 좋을 것 같습니다
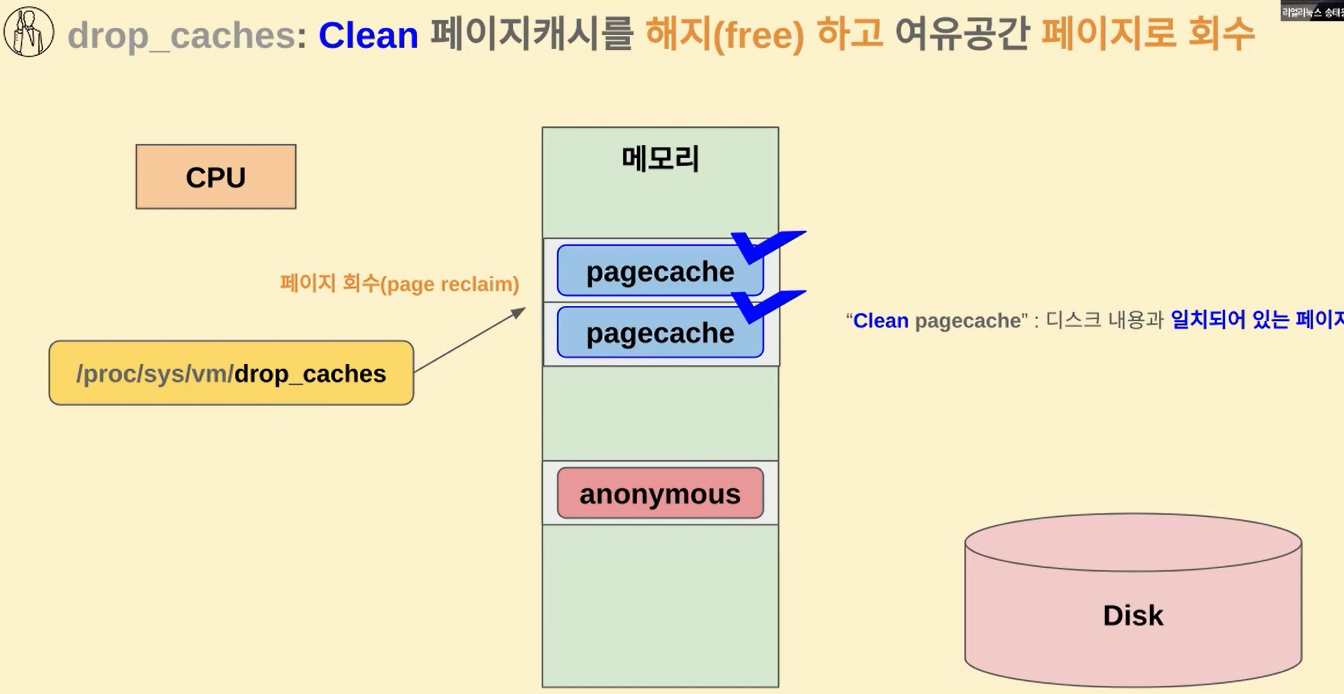
자 여기서 drop_caches 를 하게 되면 페이지 회수 reclaim 이라는 개념이 벌어지게 되요
이게 무슨 말이냐면
일단 dirty cache들은 제외합니다
그리고 clean cache 기준으로 해서 sync가 맞춰져 있기 때문에 어차피 디스크 있는 내용이 일치가 되어 있는 상태잖아요
그러니까 미리 읽어 놨을 뿐이기 때문에 이걸 해지하게 되죠
캐시라는 건 결국에 뭡니까? 미리 읽어논 데이터에요 그런데 웹 서버에서 웹 브라우저로 미리 읽어 와서 웹 브라우저 안에 있는 캐시 개념도 있을 수 있는 거고 디스크에서 메모리를 읽어서 이런 페이지 캐시 개념이 있을 수도 있는 거고요
그리고 메모리에서 cpu를 읽고 와서 SRAM에 로드(load)가 되는 CPU 캐시 개념으로 예기할 수 도 있는거에요
그래서 캐시는 여기저기서 쓰일 수 있는 (범용적으로 쓰이는) 용어 이기 때문에 조금 헷갈릴 수 있는 여지는 좀 있습니다
그래서 어느 레벨인지를 항상 구분 짓는게 굉장히 중요할 수가 있겠고 어찌됐든 지금 여기 보이는 페이지캐시는 미리 읽어 놨을 뿐이기 때문에
drop을 해도 상관이 없죠 그래서 해지를 하게 되면 이렇게 여유 공간에 페이지로 그냥 회수한다는 개념으로 그러니까 페이지가 쓰이고 있었는데
다시 도로 가져간다는 개념으로 회수라는 표현을 쓰게 되고요
이걸 바꿔 말하면 여유 공간의 페이지가 생성된다라고 볼 수가 있습니다 이런 식으로 drop_caches 벌어질 수가 있죠
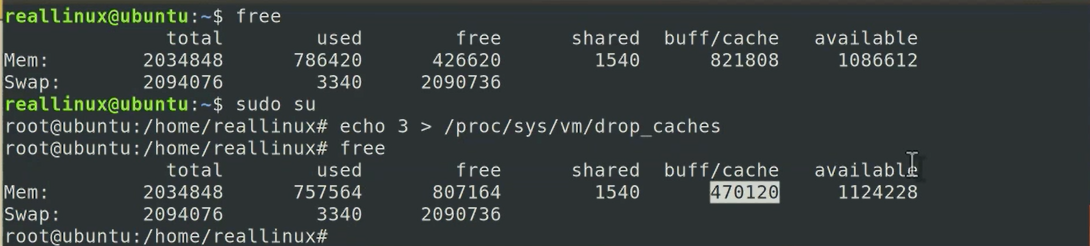
한번 해보도록 할게요 free 명령을 했을 때 pagecaches 그러니까 buff/cache 이렇게 차지하고 있는 걸 볼 수가 있는데요
sudo권한이 필요해요 루트 계정에서 진행하는게 필요할 수가 있겠고요
여기서 echo 3이라고 하게 되면 여기 보이는 캐시들 중에서 내용 버퍼든 아이노드 버퍼든 그리고 또 (파일)경로를 관리하게 되는 덴트리(Dentry)
정보라는 그런 캐시들도 전부 다 해지하게 돼요 그래서 경로 정보, 파일에 대한 경로정보 캐시 되어 있는 거 그리고 데이터 블록 캐시 되어 있는 거
아이노드 블록 캐시 되어 있는 것 전부 다 drop을 할 수 있습니다
echo 3을 하게 되면 proc/sys/vm/drop_caches free를 하게 되면
이렇게 현저히 줄어든 것을 볼 수가 있겠죠 그래서 이런 식으로 sync하고 drop_caches는 전혀 다르고요
보통 drop_caches를 할 때는 먼저 sync를 하라는 말을 많이 해요
그 이유를 좀 이해할 수 있으려면 차이점을 이해하는게 굉장히 중요할 수 있겠고요
다시 한번 말씀드리지만 난이도 좀 있는 겁니다
굉장히 좀 개념이 어려울 수 있어요
그래서 이런 것들을 조금 더 집중해서 공부하고 싶으시면
리얼리눅스 시스템 핵심정리와 중급A 과정을 함께 공부해 주시면 좋을 것 같고요
drop_caches 공부할 때는 여기 보이는 man proc 매뉴얼 파일 안에서 조금 더 살펴볼 수가 있습니다
drop_caches를 보게 되면은 보이시는 것처럼 echo 1, echo 2, echo 3 이런 것들 보이잖아요
우리가 방금 했던 건 echo 3이에요
그런데 여기서 조금 구분하셔야 되는 건 여기는 페이지 캐시고 여기는 아이노드인데요
선생님께서 말씀하실 때는 페이스캐시 부분이 아이노드 저장하고 있는 buffs, caches든 전부 다 pagecaches라고 말씀하셨잖아요 맞습니다
얘도 pagecaches가 맞아요 이거는 제가 증명을 해드릴 수가 있습니다
커널 소스 코드 안에서도 그렇게 관리가 되고 있고요 똑같은 페이지만 pagecaches 용도로 쓰고 있는 것은 같아요
내용이 잠겼는지 파일 정보가 담겼는지인 거죠 그러니까 얘도 사실은 pagecaches가 맞습니다
하지만 여기서 말하는 pagecaches는 데이터 블록들을 기준으로 해서 말씀을 드리는 거고요
여기는 pagecaches 중에서도 아이노드 정보를 담고 있는 걸 얘기하게 되는 거죠
그래서 그렇게 구분하시는것이 중요하겠고 dentries는 말씀드렸던 것처럼 파일의 경로 정보를 리눅스커널 안에서 캐시가 되어 있습니다
미리 정보가 어느 정도 저장되어 있는게 있어요 자주 접근하는 경로라든지 이런 것들을 들고 있거든요
그래서 이런 것들을 선별적으로 drop을 할 수도 있습니다
이런 식으로 drop caches하고 sync에 대한 차이점과 좀 기본적인 Buffered I/O pagecaches 개념들을 알아봤는데요
난이도가 조금 있는 내용들이기 때문에 한번 반복해서 공부를 해보셨으면 좋을 것 같습니다
감사합니다
관련내용에 대한 리얼리눅스에서 추천드리는 강의
리눅스 시스템 핵심정리 :https://reallinux.co.kr/course/se_system
최신 리눅스 메모리, 파일I/O 심층 분석 리눅스 커널 중급 A : https://reallinux.co.kr/course/linux_kernel_a