


안녕하세요
오늘은 인터넷과 웹사이트가 어떻게 동작하는지에 대한 주제로 한번 말씀을 드려보려고 합니다
리얼리눅스의 송태웅 강사입니다.
인터넷하고 웹사이트 결국에 네트워크 동작을 얘기하게 되는 거구요
우리가 웹 통신이 가장 중요한 내용입니다 우리가 많이 이해해야 되는 내용이고요
하나씩 한번 설명을 드려보도록 할게요 웹 클라이언트 그리고 웹 서버까지 구조를 정말 이해하는 게 상당히 중요하고요
사실 오늘 영상에서 말씀을 드리는 것은 좀 짧은 내용이기 때문에 네트워크에 대한 내용들을 좀 전반적으로 정확하게 이해하고 계시고 싶으시다면
리얼리눅스 강의 중에서 네트워크 완전 정복 수업이 있습니다
그런 것들도 참고하셔도 좋을 것 같습니다
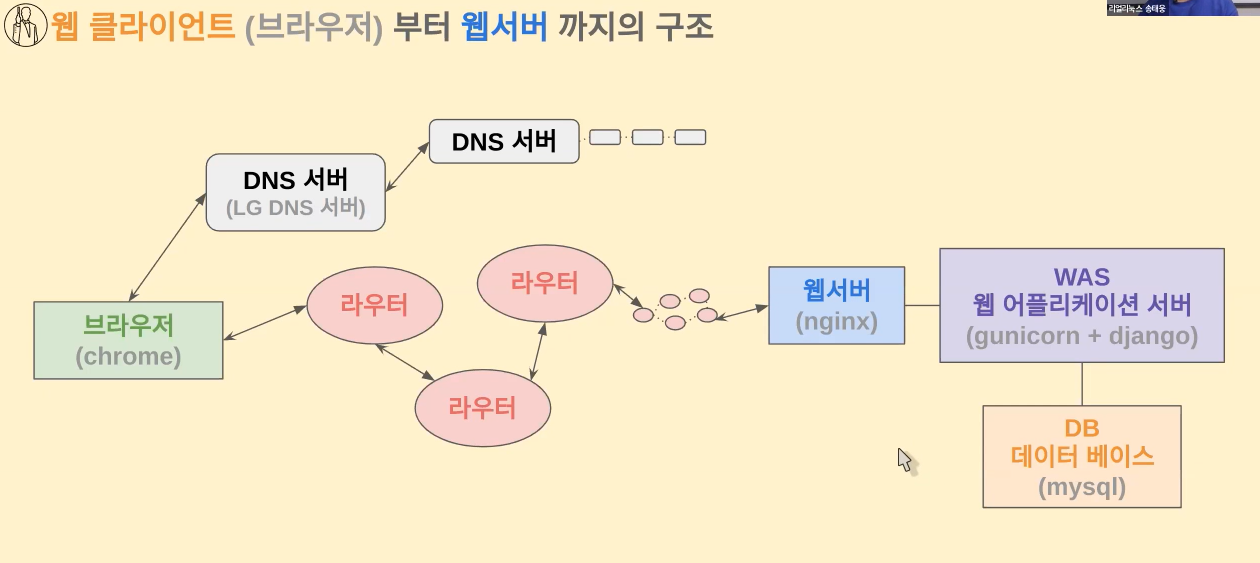
일단은 웹사이트 클라이언트하고 웹서버 구조를 말씀을 드려보도록 할게요 일단 브라우저하고 웹서버 그 관계가 있잖아요
이 웹서버라는 것은 사실 우리가 사용할 수 있는 어떤 네이버 카카오톡 혹은 구글 웹서버 이런 것들이 존재할 수가 있겠고요
그런곳에서 서버 역할을 하는 프로그램이 동작되는데 아파치 톰캣 이라든지 뭐 아니면 nginx라든지 다양한 웹서버들이 있구요
서버 프로그램하고 통신을 하면서 웹브라우저가 html, css, java script 이런 파일들을 받아서 동작되는 구조라고 보실 수 있습니다
그 과정에서 어떤 구조들을 띄는지를 하나씩 하나씩 이해하는 것이 먼저 필요해요
일단 하나씩 하나씩 말씀을 좀 드려보면 첫번째로는 DNS 입니다
DNS는 DNS통신이라는 게 있고요 DNS(Domain Name System) 서버 라고 해서 도메인 네임 시스템이라고 해서 google.com 이라든지
naver.com 이라고 적혀져 있는 도메인 주소가 있어요 도메인 주소로는 실제 네트워크 통신을 할 수는 없습니다
실제 IP 주소가 있어야지 통신을 할 수 있거든요 그래서 DNS(Domain Name System) 서버에게 물어보게 되죠 DNS 서버에게 물어봐서 이런 정보,도메인 주소를 IP 주소로 변환하는 걸 하게 되요
그게 첫 번째로 필요한 통신입니다
그 다음에 라우터를 통해서 우리가 패킷을 전달시키게 되죠 네트워크 기본 개념을 정말 정확하게 이해하고 계시는 게 중요한데
여기서 한번 요약해서 말씀을 드려보자면 네트워크의 동작 진짜 원리는 결국에 옆으로 전달이에요
그러니까 우리가 수업 도중에 예를 들어서 학교를 다닐 때 중학교,초등학교때든 쪽지 같은 거라든지 물건을 옆으로 전달하거나 뒤로 전달하거나 이런 적이 있으셨을 거에요 그것과 사실은 동일한 원리입니다 이 패킷이라고 하는 네트워크 데이터를 근처에 있는 하드웨어 장비들을 통해서 계속 옆으로 전달하는 방식이에요

그래서 그런 일련의 패킷을 옆으로 옮겨가면서 목적지까지 전달하는 과정을 라우팅 과정이라고 보통 말을 하게 되구요 이 라우터들을 장비를 통해서 지금 우리가 사용하고 있는 네트워크와 다른 네트워크를 연결해서 패킷을 전달할 수 있게 됩니다
예를 들면 카페 들어가서도 하나의 네트워크, 여러 개의 컴퓨터들이 연결되어서 네트워크 장비들이 네트워크를 이루고 있는데 그런 네트워크들이 옆에 있는 카페, 옆에 있는 빌딩, 옆에 있는 지역, 옆에 있는 나라 이런 식으로 이제 옮길 수가 있어요
그러니까 지금 우리가 쓰고 있는 망 몇 대, 20대가 됐든 30대가 됐든 여기 이외에 다른 네트워크 망과 연이어 주는 게 결국 라우터 장비구요
꼭 라우터 장비와 라우터 장비 사이가 아니더라도 이 패킷을 전달해 가는 과정을 라우팅 과정이라고 말할 수 있습니다
그냥 옆으로 계속 전달을 하게 되는 거예요 유선으로 연결됐든 무선으로 연결됐든 그런 식으로 패킷을 전달하게 되는데 패킷을 가지고 네트워크 통신하는 프로토콜 그러니까 약속이죠
네트워크 통신하는 거에 대한 약속이 여러가지가 있어요 그 중에서 TCP / IP 통신을 우리가 정말 많이 쓰죠
예를 들어서 SSH 통신 한다던가 아니면 HTTP 통신 한다던가 이런 것들 전부 다 TCP/IP 통신 기반으로 동작이 되는 거고요
TCP/IP 통신이라는 원리를 기반으로 해서 우리가 사용할 수 있는 통신이라고 말씀드렸던 SSH 통신 이외에도 http통신을 통해서 우리가 웹서버하고
Request / Response 라는 방식으로 통신을 하게 되죠 그래서 우리가 브라우저를 켜 놓고 바로 웹사이트를 접속하면서도 테스트 해볼 수가 있구요
예를 들어서 naver.com 이렇게 접속하게 되면 네이버 페이지에 접속을 하게 되잖아요
이런 거든 curl이라는 방식을 통해서 www.google.com 이라는 것을 웹사이트를 통해서도 접속할 수 있지만 이렇게 터미널을 통해서도 이렇게 html을 바로 받을 수가 있어요 이런 식으로 접속을 하는 방법도 있습니다
이런식으로 하는 것이 결국에는 클라이언트 사이드가 브라우저냐 아니면 이렇게 curl처럼 커맨드 라인을 기준으로냐 이런 식으로 될 수 있겠고 웹서버와 통신은 이런 식으로 이루어질 수가 있습니다
그 과정 속에서 이런 과정들을 전체적으로 거치게 되요 말씀을 드린대로 이 브라우저라는 것은 google.com, naver.com 이런 도메인 주소를 입력할 수 있고요 도메인 주소만으로는 네트워크 통신이 안된다고 말씀드렸어요 이건 그냥 문자열일 뿐이에요
그래서 이거를 DNS 서버를 통해서 변환을 시키게 되죠 그래서 IP address로 변환해서 받을 수 있겠고 웹서버랑 통신을 해서 그리고 웹서버로 또 받는건 HTML 코드, Java Script 코드, 그리고 이미지 파일, 영상파일 여러가지 이런 파일들을 웹 서버로부터 받아서 웹 브라우저가 그걸 출력해서 그린다라고 생각을 해주실 수 있습니다 말씀을 드린대로 이렇게 www.google.com으로는 네트워크 통신이 불가능해요

그래서 DNS 서버에게 물어볼 수가 있겠구요 DNS 서버는 LG, KT, SK 여러군데 있구요 꼭 거기가 아니더라도 IP주소 8.8.8.8
이런 구글 DNS서버 주소도 존재하고 있습니다 전세계적으로 DNS 서버가 굉장히 여러개가 존재하고 있고요
그래서 우리 근처에 있는 DNS 서버한테 물어봤는데 몰라 그러면 그 DNS 서버가 다른 DNS 서버한테 물어봐서 www.google.com 에 IP address가 뭐야? 아니면 내가 도메인 주소를 새로 샀어 abcd.com 을 샀어요 abcd.com이 IP address가 뭐야 라는 거를 DNS 서버에게 물어보게 되고요
우리가 도메인 주소만 사고 서버 주소를 연결을 안 해놓으면 이게 또 그 서버 주소를 리턴해 줄 수가 없기 때문에 우리가 그 웹사이트에 또 접속을 못 하겠죠
그리고 IP address 연결을 한다고 하더라도 실제 80포트를 기준으로 해서 웹서버 프로그램이 구동되고 있지 않다면 또 접속이 안 될 겁니다
그래서 어쨌든 우리가 DNS를 통해서 도메인 주소를 IP address 변환하는 과정을 거칠 수가 있겠고요 그 다음에
IP address를 얻어내서 TCP/IP 통신을 시작하게 되는데 사실 TCP/IP 통신은 커넥션을 맺고 finish 그러니까 해지를 하는 과정이 있어요
그래서 그 과정도 뒤에서 간단하게 설명을 드리겠지만 어쨌든 커넥션과 그리고 또 해지 과정을 3-way handshake라는 방법과 4-way handshake라는 방법으로 하게 되고요
그 다음에 패킷이 주고 받을 때 결국에 이 HTTP 통신을 하면서 내부적으로는 tcp IP 통신을 하게 되고요 패킷을 라우터와 라우터 사이를 건너가면서
결국에 주고받게 되죠 그래서 어떤 라우터들을 거쳐서 구글 서버까지 도착했을까를 우리가 명령어로 증명해 볼 수가 있는데요
예를 들어서 raceroute라는 명령어를 통해서 할 수가 있습니다 n을 하게 되면 도메인 주소 대신에 IP 주소로 확인을 할 수가 있어요
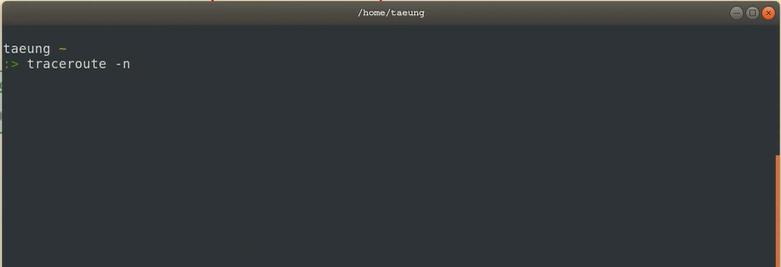
그래서 www.google.com 입력하게 되면 총 몇 개의 라우터들을 거쳐서 우리가 패킷을 전달하게 되고 받게 되는지를 확인할 수 있고 요거 같은 경우에는 확인하는 패킷이라고 볼 수 있는 ICMP 패킷을 활용해서 체크를 하게 됩니다
그래서 구글 서버하고 우리 서버와의 관계 때문에 이게 라우터들을 뭘 거쳤든지 옆으로 전달 옆으로 전달 이걸 몇 번까지 해가지고 13번까지 해서
도착을 했다는 사실을 알 수가 있는 거죠 그래서 이런 식으로 traceroute라는 것을 통해서 확인할 수가 있겠고요 하지만 traceroute가 만능은 아닙니다
예를 들어서 뭐 naver.com 같은 거를 했을 때 정상적으로 결과가 안 나올 수가 있어요 그 이유는 뭐냐면 네이버 같은 경우에는 TCP/IP 통신 웹서버,HTTP통신 이런 것들은 정상적으로 할 수가 있겠지만 이제 ICMP라고 해서 확인을 하고 테스트 용도로 점검하는 패킷은 응답을 안 해줄 수가 있습니다 그렇게 되면은 traceroute 정상적으로 확인이 안 돼요 그래서 ICMP 패킷을 허용하냐 허용하지 않느냐에 따라서 이런 부분들이 동작을 안 할 수도 있습니다
사실 여기서 이제 많은 얘기들을 하고 싶지만 워낙 짧은 영상이기 때문에 조금 한계점이 있구요 하지만 이제 우리 리얼리눅스 수업을 통해서 또 같이 공부를 하시게 되면 다양한 명령어를 통해서 한번 증명도 해보고 추적도 해보고 이런 실습들 진행해보면 참 좋을 것 같습니다 자 traceroute명령어 이렇게 적어 놨고요 TCP/IP 통신 기반으로 HTTP통신이 동작된다고 말씀을 드렸고요

그래서 내부적으로 SYN, SYN/ACK, ACK 라는 방식을 통해서 3 way handshake로 커넥션을 맺는 과정이 반드시 먼저 들어갑니다 그래서 먼저 커넥션을 맺게 되구요 ESTABLISH 상태에서 HTTP통신으로 Request / Response GET 요청,POST 요청 이런 것들을 할 수가 있겠구요
그 다음에 4-way handshake라는 방식을 통해서 커넥션을 해지시킬 수 있어요 HTTP통신의 특징 중에 하나는 ESTABLISH 상태를 계속 유지하지 않습니다
커넥션을 맺었다가 ESTABLISH 상태에서 Request/Response 를 하고 나서 바로 4 -way handshake로 끊게 돼요 보통 그렇게 되면 계속 연결했다 해지했다 연결했다 해지했다 좀 오버헤드라고 생각하실 수도 있겠지만 실제로 웹통신 같은 경우에 특히나 접속자가 너무 많을경우에는 커넥션을 계속 유지하는 것 자체가 서버에 부하거든요 그래서 커넥션을 계속 유지한다기 보다는 커넥션을 맺었다가 GET 요청, POST 요청 Request/Response 를 하고 나서 해지를 시키는 게 일반적이라고 볼 수는 있어요 여기서 조금 더 깊게 들어가 보면 TCP/IP 통신 같은 경우에도 keep alive 또 HTTP 통신 같은 경우에 keep alive 개념이 있어요 그래서 이 연결 상태를 조금 더 유지하는 그런 관련된 설정들이 있는데요
그런 것들은 기회가 되면 다른 영상으로 이야기 해보면 좋을 것 같구요 당연히 우리는 수업 안에서도 다루는 내용 중에 하나입니다
어쨌든 이렇게 말씀을 드릴 수가 있겠구요 연결 종료 해지가 됐을 때 finish 과정을 거칠 수가 있어요 그때 4 -way handshake 이라고 해서 과정을 거치게 되고요 이런 부분들을 간단하게 추적을 해보면서 웹사이트 동작원리 그리고 인터넷 네트워크 동작 원리에 대해서 간단하게 웹 통신을 기반으로 해서 알아보는 시간을 마무리하면 좋을 것 같아요 일단은 tshark라는 것을 다운로드 받을 수 있습니다 윈도우에서는 wireshark라고 해서
GUI 환경으로 볼 수 있는 것들이 있는데요
우리가 AWS나 GCP라든지 클라우드를 사용한다던가 일반적인 리눅스 서버를 사용하게 되면 GUI 환경을 사용할 수가 없어요
그렇기 때문에 tshark 같은 걸 통해서 패킷을 추적해 볼 수가 있겠고요 tcpdump라든지 tshark 같은 것들 잘 쓰는 거 굉장히 중요합니다
계속 말씀드릴 수 있겠지만 리얼리눅스 수업 안에서는 계속 실습하고 추적하는 것들을 많이 하거든요 그렇기 때문에 그런 명령어들을 많이 활용을 하죠 그래서 여러분들도 꼭 저희 수업을 듣지 않는다고 하더라도 내가 공부한 내용들을 다양한 추적 도구, 모니터링 도구를 통해서 항상 증명하면서
공부하는 법을 들으시면은 실력이 많이 향상 시킬 수 있다고 생각이 듭니다 일단은 tshark는 설치가 되어 있어서 apt-get install tshark 는 생략하고 tshark를 한번 보여드리도록 할게요 일단은 enp0s3는 eth0, eth2, eth1 이런 것처럼 네트워크 인터페이스를 뜻하게 되는 거고요
여기서 tcp 포트 번호를 기준으로 해서 이제 추적을 한번 해볼 거예요
포트 80 이렇게 추적을 걸어 놨는데 추적 결과가 전혀 안 나오고 있는 걸 볼 수 있습니다 그 이유는 뭐냐면 트레이싱, 추적 이런 걸 걸어 놨지만
지금 80 포트를 사용하는 게 전혀 없기 때문이에요 추적을 걸어 놓은 거에 맞춰 가지고 우리가 한번 실제로 curl 명령이라든지 웹사이트 접속을 한번 해봐야겠죠
그래서 www.google.com을 입력을 해보도록 하겠습니다 이렇게 하면 추적 결과가 나오는 걸 볼 수 있어요 추적 결과가 워낙 복잡하게 나오기 때문에
하나하나 다 설명드리긴 조금 한계가 있겠지만 우리가 공부했던 3 way handshake 그러니까 SYN, SYN/ACK, ACK이런 방식들이 동작되는게 어느 포트에서 어느 포트로 어느 IP address 에서 어느 IP address로 오고 갔는지 이런 것들을 자세하게 볼 수가 있겠고요 이 밑에도 FIN+ACK / ACK / FIN+ACK / ACK 그러니까 4 -way handshake에 대한 부분들도 나오는걸 볼 수 있는데요
이와 같은 경우에는 우리가 이제 정석으로 4 -way handshake를 공부한 거하고 패킷이 조금 다르게 보이는 걸 볼 수 있을 거에요
이런 것들도 결국에는 실제로 추적해 봐야지 알 수 있는 내용들이고요 자세한 부분들은 또 수업 내용 때
한번 더 달아보면 참 좋을 것 같습니다 자 여기서 한 가지만 좀 말씀드려볼께요
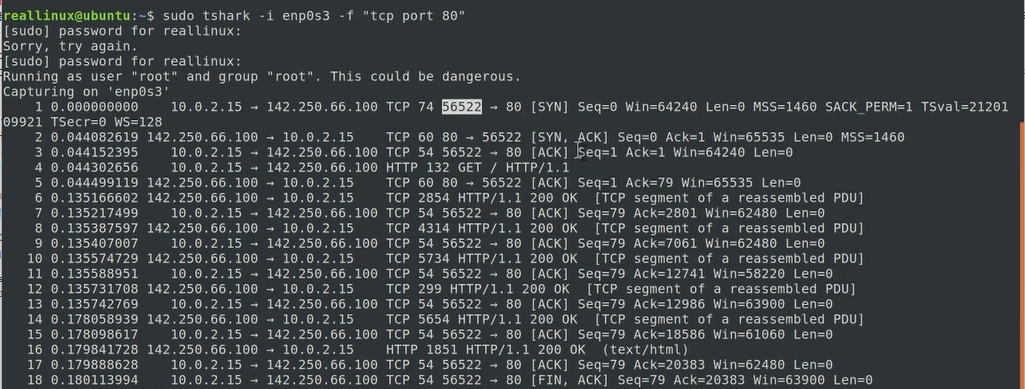
우리가 웹통신을 한다고 하면 80포트를 쓴다고 하니까 웹 클라이언트 그러니까 브라우저라든지 curl 같은 경우에도 80포트를 똑같이 쓴다라고 생각하시는 분들이 있는데요 절대 그렇지 않습니다 웹 서버가 80포트를 쓰는 거예요 여기 보이시는 것처럼
56522 라고 적혀있는 클라이언트 포트번호가 보이시죠 클라이언트 포트 번호는 여러가지로 달라질 수가 있는 거구요 웹서버가 80포트를 쓸 수 있는 거에요 그리고 우리가 포트 번호 외워야 되는 3가지 있었죠 기억나시나요? ssh는 22번 그리고 http통신은 80포트 그리고 https는 443 포트 번호 있었습니다
여기까지 해서 인터넷과 웹사이트 동작에 대한 기본적인 부분들을 압축적으로 좀 알아봤고요 좀 더 자세한 내용들은 또 다른 영상이나 수업을 통해서 한번 말씀을 좀 드려보면 참 좋을 것 같습니다 자, 감사합니다